LaTeX 渲染有问题。将就着看吧。
类型
芯片内部总线
系统总线
通信总线
# 总线结构
# 数据线
在系统组件之间传输数据
数据线的数量决定了一次可以传输的数据的大小
# 地址线
在数据线和地址 I/O 端口上指定数据的来源和去向
地址线的数量决定了寻址空间的大小
即:如果寻址空间为 2^32,那么地址线有 32 根
两台地址线数量相同的计算机,寻址空间的大小一样吗?
其理论寻址空间是相同的,但 实际寻址空间大小 和 使用方式 可能不同,取决于多种其他因素。
# 控制线
控制对数据线和地址线的存取和使用
・时钟(clock):用于总线同步操作
・总线请求(bus request):表示模块需要获得对总线的控制
・总线允许(bus grant):发出请求的设备已经被允许控制总线
・中断请求(interrupt request):表示某个中断正在悬而未决
・中断响应(interrupt ACK):未决的终端请求被响应
・存储器读(memory read):从存储器读数据到总线
・存储器写(memory write):将数据从总线写入存储器
・I/O 读(I/O read):从 I/O 端口读数据到总线
・I/O 写(I/O write):将数据从总线写入 I/O 端口
• ……
# 总线上数据传输的特点
总线可以被多个设备监听,但同一时刻只能由一个设备发送数据
当总线在被使用过程中,其它设备不可以抢占
如果设备想发送数据 / 请求数据,需要先获得总线的使用权
# 设计要素
# 用途
专用(dedicated)总线:始终只负责一项功能,或始终分配给特定的计算 机组件
复用(multiplexed)总线:将同一线路用于多种用途
# 仲裁与仲裁方案
当多个设备需要与总线通信时,通过某种策略选择一个设备
仲裁方案:
集中式(centralized):由仲裁器(arbiter)或总线控制器(bus controller)负责分配总线使用权
链式查询 / 菊花链
计数器查询
独立请求
分布式(distributed):每个设备都包含访问控制逻辑,各设备共同作用分享总线
自举式
冲突检测
# 链式查询
所有的设备都是串行连接的,并将允许信号从优先级最高的设备下发到优先级最低的设备。
总线仲裁器收到请求后,在总线不忙的前提下,发起允许信号
如果某个设备收到了允许信号并且发起了总线请求,该设备将总线设置为繁忙状态,允许信号将不再被进一步传递
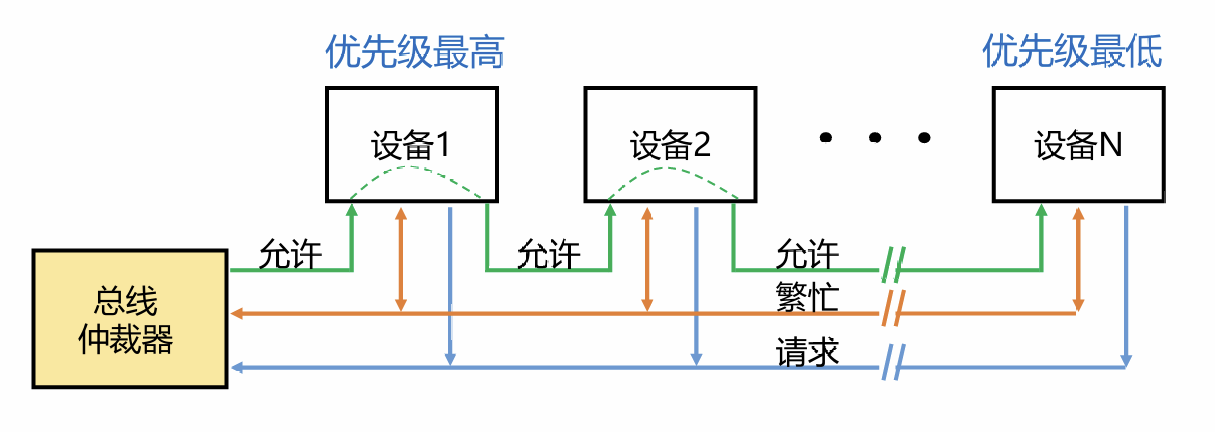
确定优先级简单,可以灵活添加设备,但是不能保证公平性,限制总线的速度。
# 计数器查询
将总线允许线替换为设备 ID(地址)线
当总线仲裁器收到总线请求信号,判断总线空闲时,计数器开始计数,计数值通过设备 ID 线发向各个部件
如果当前发送请求的设备 ID 等于裁决器当前的计数,裁决器将停止计数,设备将总线设置为繁忙
人话就是仲裁器依次从高往低询问每个设备要不要使用总线,如果当前设备请求总线,则赋予其总线控制权,如果没有请求,则继续查询下一个设备。
一旦某个设备获得总线控制权,其他设备需要等待其释放总线后才能竞争。
强调优先级和公平性,但是限制总线的速度。

# 独立请求
每个设备都有自己的总线请求线和总线允许线
总线仲裁器决定哪个设备可以使用总线
有很多确定策略:固定优先级,公平链式,LRU,FIFO,…
快速响应,可编程的优先级,但是逻辑更复杂,线路更多

# 自举式
固定优先级
每个设备在其总线请求线上发送请求
- 最低优先级的设备没有请求线
每个设备自行判断自己是否在请求总线的设备中优先级最高

# 时序
确定每个总线事务的开始和结束时间
# 同步时序

所有设备共享同一个时钟
# 异步时序
异步时序(Asynchronous Timing)是指总线通信过程中不依赖全局时钟,而是通过 握手信号 来协调各设备之间的操作。
分为非互锁、半互锁、全互锁。


# 半同步时序
为了减少噪声的影响,在异步计时中使用时钟
准备和响应信号在时钟上升沿有效
# 分离事务
将一个总线事件分离为两个过程
# 总线带宽和数据传输速率
总线带宽(bus bandwidth):总线的最大数据传输速率
不要考虑总线仲裁、地址传输等因素
数据传输速率
考虑地址传输、握手等因素
# 同步总线和异步总线的数据传输速率
** 例题 1:** 假设同步总线的时钟周期为 50ns,每次传输需要一个时钟周期,异步 总线每次握手需要 40ns。两个总线都是 32 位宽,内存的数据准备时间为 200ns。 当从存储器中读出一个 32 位的字时,计算两个总线的数据传输速率。
同步总线:
从存储器中读出一个 32 位的字,三个流程:
CPU 发送指令和地址到内存:50ns
内存准备数据:200ns
将数据传输回 CPU:50ns
由于一次传递 32 位,速率单位为 bps
所以:数据传输速率 = 32bit / (50 + 200 + 50) ns = 106.7Mbps
(1 ns 等于 s)
异步总线:
步骤 1:40 ns
步骤 2、3、4 / 数据准备:max (40ns* 3,200ns) = 200ns
步骤 5、6、7:40ns * 3 = 120ns
数据传输速率 = 32bit / (40 + 200 + 120) ns = 88.9Mbps

每一步的解释看上面
** 例题 2:** 假设同步总线的时钟周期为 50ns,每次传输需要一个时钟周期,异步 总线每次握手需要 40ns。两个总线都是 32 位宽,存储器的数据准备时间为 230ns。当从存储器中读出一个 32 位的字时,计算两个总线的数据传输速率。
同步总线
数据传输速率 = 32bit / (50 + 250 + 50)ns = 91.4Mbps
250 是因为需要是时钟周期的倍数
异步总线
数据传输速率 = 32bit / (40 + 230 + 120) ns = 82.1Mbps
40:步骤 1
230:max(40*3,230)
120:40*3
# 不同数据块大小的数据传输速率
** 例题 3:** 假设系统具有以下特征:
它支持访问大小为 4 到 16 个字(每个字 32 位)的块
同步总线具有 64 位宽和 200MHz 时钟频率,需要 1 个时钟周期来传输地址或 64 位数据
在两个总线事务之间有 2 个空闲时钟周期
内存访问时准备前 4 个字需要 200ns,后面每 4 个字准备需要 20ns
当前面的数据在总线上传输时,内存可以同时读取后面的数据
如果读取 256 个字,分别计算每次传输 4 个字和 16 个字时的数据传输速率、 传输时间和每秒总线事务数
每次传输 4 个字:
200MHz 时钟频率 → 5ns 一个时钟周期
先计算总共的时间周期:
总线事务:传地址+传 4 个字
地址传输:需要 1 个时钟周期
数据准备:需要 200ns (40 个时钟周期)
数据传输:2 个时钟周期(一个时钟周期传输 64 位,4*32/64=2)
空闲:2 个时钟周期
总共传 256 个字,256/4=64,传 64 次
因此总共:64*(1+40+2+2)=2880 个时钟周期
传输时间:2880 * 5 ns = 14400 ns
每秒总线事务数:
单次时间:(1+40+2+2)*5=225ns
每秒总线事务数 = 1s / 225ns = 4.44M
数据传输速率:总传输数据量 / 总时间
256 * 32bit / 14400ns = 568.9Mbps
每次传输 16 个字:
先计算总共的时间周期:
总线事务:传地址+传 16 个字
地址传输:需要 1 个时钟周期
数据准备(前四个字):需要 200ns (40 个时钟周期)
数据传输:2 个时钟周期(同时读取后 4 个字:20ns,4 个时钟周期)
空闲:2 个时钟周期
总共传 256 个字,256/16=16,传 64 次
因此总共:16 *(1+40+ 3 * max(2 , 4)+ 2+2)= 912 个时钟周期
解释一下,还是一次传 4 个字,16 个字传 4 组。在传第 1 组时,同时读取第 2 组数据,4>2 所以耗费 4 个时钟周期,同理传第 2 组读第 3 组,传第 3 组读第 4 组,都是 4 个时钟周期。传第 4 组时,不用读数据了,因此 2 个时钟周期即可。
传输时间: 912 * 5 ns = 4560 ns
每秒总线事务数:
单次时间:(1+40+ 3 * max(2 , 4)+ 2+2)*5=285ns
每秒总线事务数 = 1s / 285ns = 4.44M
数据传输速率:总传输数据量 / 总时间
256 * 32bit / 4560ns = 1796.5Mbps
# 提高总线的数据传输率
提高时钟频率(时钟周期数不变的情况下)
增加数据总线宽度,每次传输更多的数据
块传输,传输一次地址就传输一块数据
分离总线事务,减少总线空闲时间
分离地址线和数据线,同时传输地址和数据
# 总线层次结构
# 单总线结构
CPU、存储器和 I/O 模块都连接到一条系统总线
# 双总线结构 I

在 CPU 和存储器中间增加一个存储器总线
增加 CPU 和存储器之间的传输效率,同时降低系统总线的负担
# 双总线结构 II
将系统总线分为存储器总线、I/O 总线 和 IOP(input/output processer)
降低 I/O 对总线的负担

# 多总线结构
都是增加 I/O 交互效率的。略